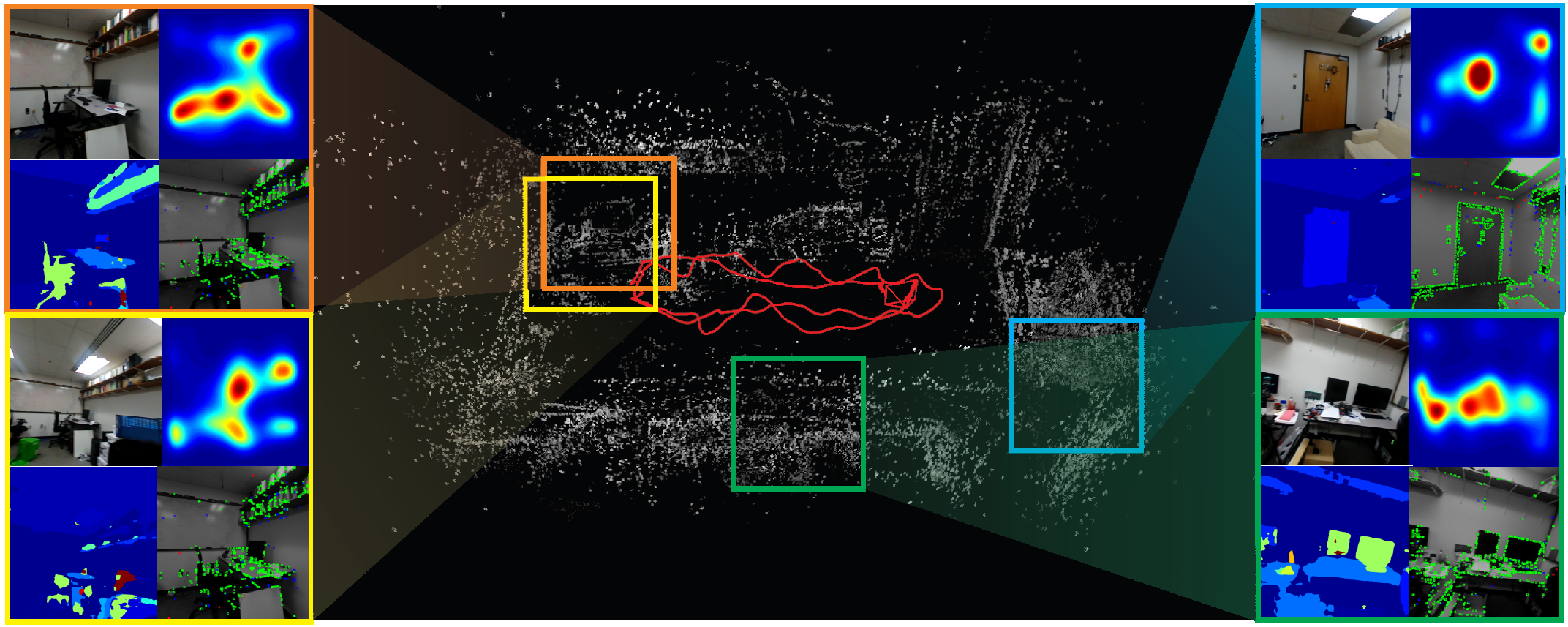
Fig. 1: Sample point-cloud output of SalientDSO which does not have loop closure or global bundle adjustment. The insets
show the corresponding image, saliency, scene parsing outputs and active features. Observe that features from non-informative
regions are almost removed approaching object centric odometry.
Although cluttered indoor scenes have a lot of
useful high-level semantic information which can be used
for mapping and localization, most Visual Odometry (VO)
algorithms rely on the usage of geometric features such as
points, lines and planes. Lately, driven by this idea, the
joint optimization of semantic labels and obtaining odometry
has gained popularity in the robotics community. The joint
optimization is good for accurate results but is generally very
slow. At the same time, in the vision community, direct and
sparse approaches for VO have stricken the right balance
between speed and accuracy.
We merge the successes of these two communities and present
a way to incorporate semantic information in the form of visual
saliency to Direct Sparse Odometry - a highly successful direct
sparse VO algorithm. We also present a framework to filter
the visual saliency based on scene parsing. Our framework,
SalientDSO, relies on the widely successful deep learning based
approaches for visual saliency and scene parsing which drives
the feature selection for obtaining highly-accurate and robust
VO even in the presence of as few as 40 point features per frame.
We provide extensive quantitative evaluation of SalientDSO on
the ICL-NUIM and TUM monoVO datasets and show that
we outperform DSO and ORB-SLAM - two very popular
state-of-the-art approaches in the literature. We also collect and
publicly release a CVL-UMD dataset which contains two indoor
cluttered sequences on which we show qualitative evaluations.
To our knowledge this is the first paper to use visual saliency
and scene parsing to drive the feature selection in direct VO.
