Motivated by Goldman's Theory of Human Action-a framework in which action decomposes into 1) base physical movements,
and 2) the context in which they occur-we propose a novel learning formulation for motion and context, where context
is derived as the complement to motion. More specifically, we model physical movement through the adoption of Therbligs,
a set of elemental physical motions centered around object manipulation. Context is modeled through the use of a
contrastive mutual information loss that formulates context information as the action information not contained within
movement information. We empirically prove the utility brought by this separation of representation, showing sizable
improvements in action recognition and action anticipation accuracies for a variety of models. We present results over
two object manipulation datasets: EPIC Kitchens 100, and 50 Salads.
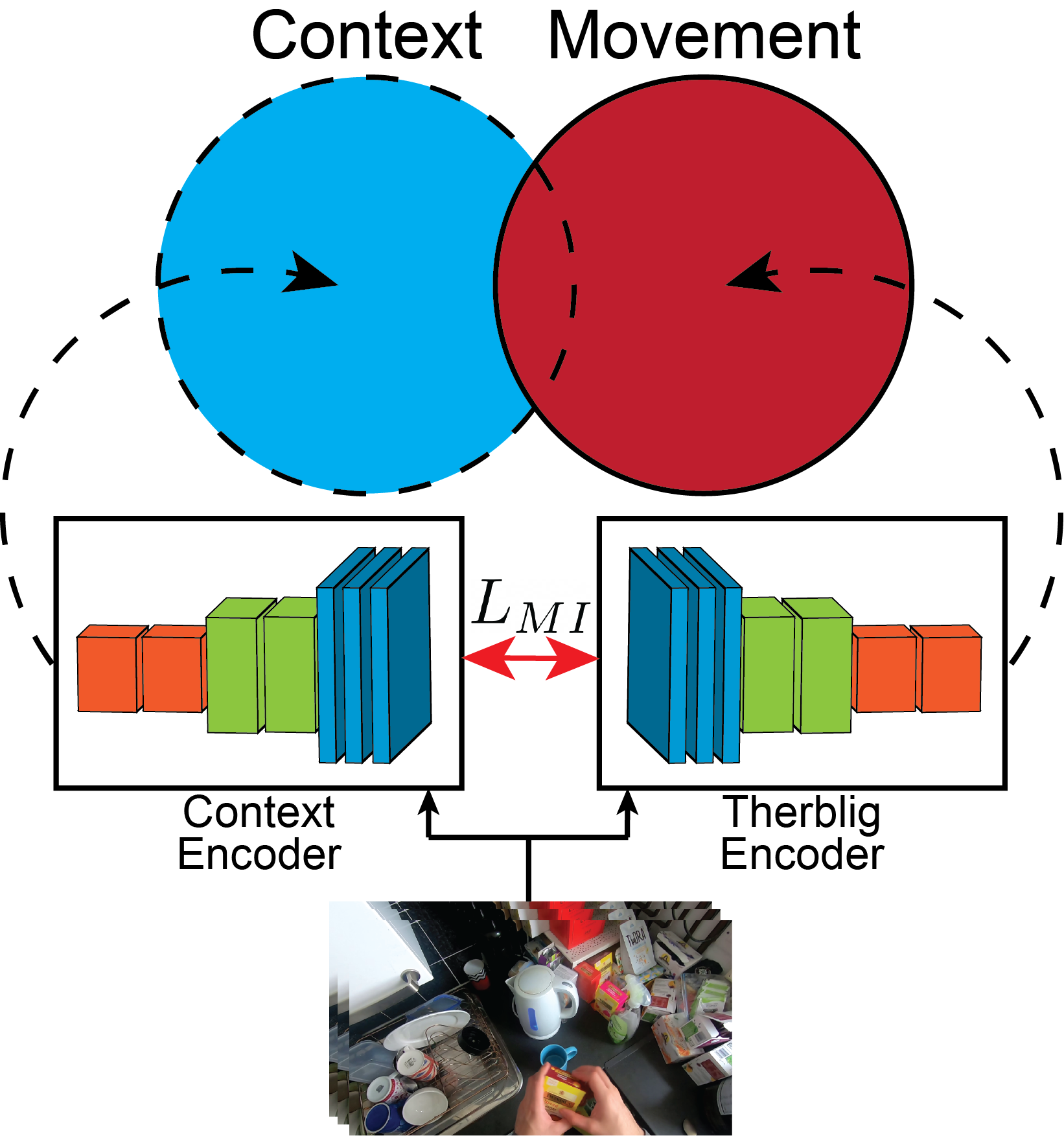
Conceptual illustration of our proposed framework, which models motion representations separate from contextual representations, where these representations are constrained to be complementary through a contrastive loss formulation $L_{MI}$. We employ two streams: A Context Encoder and a Therblig Encoder. The Therblig Encoder maps video to representations of movement. The Context Encoder models representations of action complementary to representations of movement produced by the Therblig Encoder. Together, they capture information pertaining to the relevant aspects of action.

Example sequences from the EPIC Kitchens dataset where contextual information plays a large role in the interpretation of action. Sequences listed from top to bottom: (A) the tray is emptied after the removal of each object inside, and so the action becomes \textit{empty the dish rack}, (B) the asparagus is wet prior to its placement in the drainer, and so the action becomes \textit{drain water from asparagus}, (C) the stove is turned on throughout the flipping of the food inside the pan, and so the action becomes \textit{cook the mix inside the pan}. In each of these examples, understanding the base movement being performed is insufficient to arrive at a full understanding of the high level action being performed. Only when context is incorporated does the full nature of the action become apparent.
