Abstract
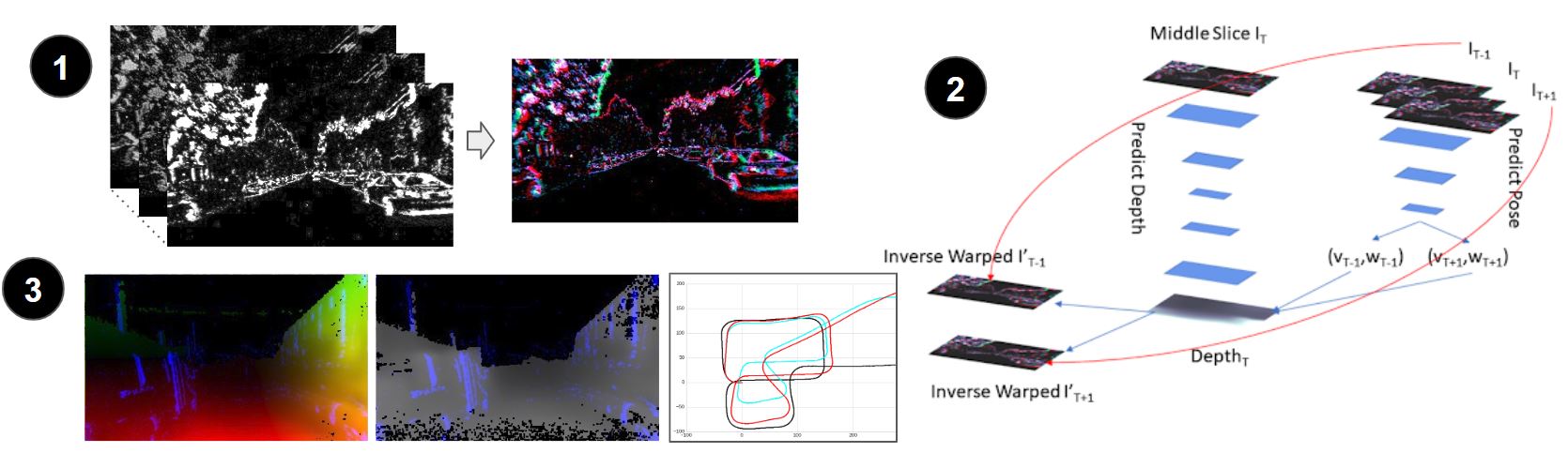
Fig. 1. The outline of our pipeline: (1) The input to the neural network is a 3-channel image, containing per-pixel positive and negative event counts and an average timestamp. (2) The low-parameter neural network uses a single image to predict depth, and from 5 to 9 images to predict egomotion. The error, based on the computed optical flow is then backpropagated, allowing for self-supervised learning. (3) The output of the pipeline is the dense optical flow, depth and velocity, which is used to reconstruct car trajectory.
In this work we present a lightweight, unsupervised learning pipeline for dense depth, optical flow and egomotion estimation from sparse event output of the Dynamic Vision Sensor (DVS). To tackle this low level vision task, we use a novel encoder-decoder neural network architecture - ECN. Our work is the first monocular pipeline that generates dense depth and optical flow from sparse event data only. The network works in self-supervised mode and has just 150k parameters. We evaluate our pipeline on the MVSEC self driving dataset and present results for depth, optical flow and and egomotion estimation. Due to the lightweight design, the inference part of the network runs at 250 FPS on a single GPU, making the pipeline ready for realtime robotics applications. Our experiments demonstrate significant improvements upon previous works that used deep learning on event data, as well as the ability of our pipeline to perform well during both day and night.
Paper
|
Chengxi Ye*, Anton Mitrokhin*, Cornelia Fermüller, James A. Yorke, Yiannis
Aloimonos.
* Equal Contribution |
|
|
|