Abstract
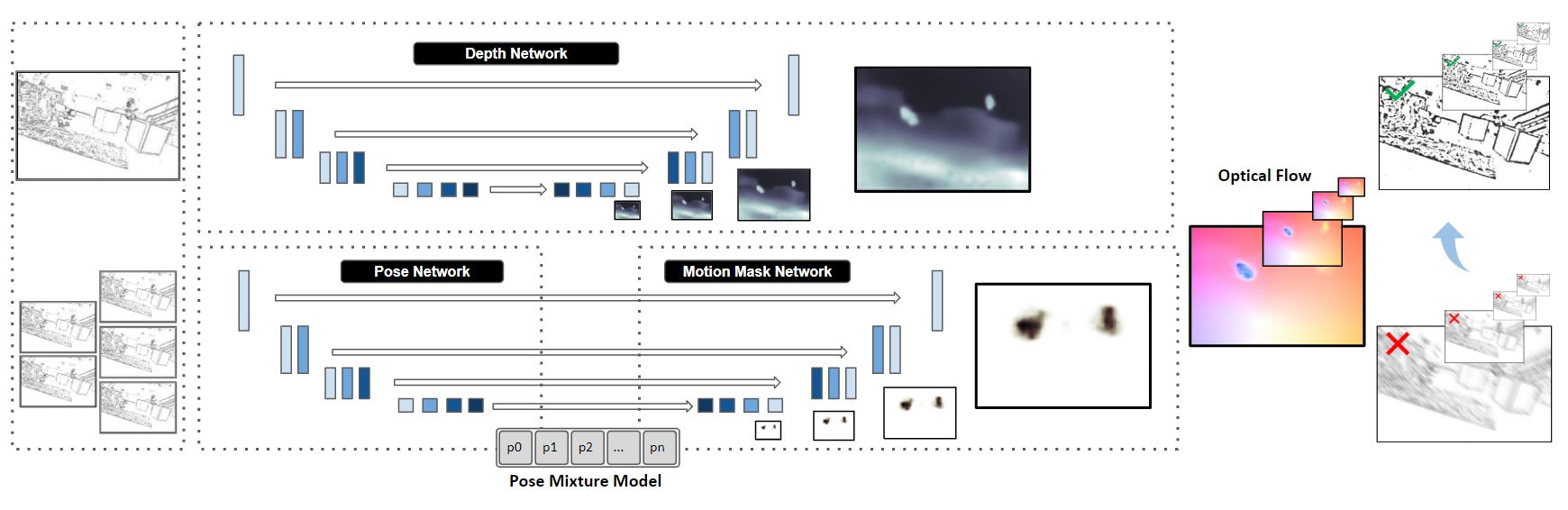
Fig. 1. A depth network (top) uses an encoder-decoder architecture and is trained in supervised mode to estimate scene depth. A pose network (bottom left) is unsupervised and takes consecutive event slices to generate a mixture model for the pixel-wise pose. A mixture of poses and mixture probabilities (bottom right) are outputs of this network. The outputs of the two networks are combined to generate the optical flow, then to inversely warp the input frames and backpropagate the error.
We present the first event-based learning approach for motion segmentation in indoor scenes and the first event-based dataset EV-IMO which includes accurate pixel-wise motion masks, egomotion and ground truth depth. Our approach is based on an efficient implementation of the SfM learning pipeline using a low parameter neural network architecture on event data. In addition to camera egomotion and a dense depth map, the network estimates pixel-wise independently moving object segmentation and computes per-object 3D translational velocities for moving objects. Additionally, we train a shallow network with just 40k parameters, which is able to compute depth and egomotion.
Our EV-IMO dataset features 32 minutes of indoor recording with 1 to 3 fast moving objects simultaneously on the camera frame. The objects and the camera are tracked by the VICON motion capture system. We use 3D scans of the room and objects to obtain accurate depth map ground truth and pixel-wise object masks, which are reliable even in poor lighting conditions and during fast motion. We then train and evaluate our learning pipeline on EV-IMO and demonstrate that our approach far surpasses its rivals and is well suited for scene constrained robotics applications.
Paper

|
Chengxi Ye*, Anton Mitrokhin*, Cornelia Fermüller, Yiannis Aloimonos,
Tobi Delbruck.
* Equal Contribution |
|
|
|
|