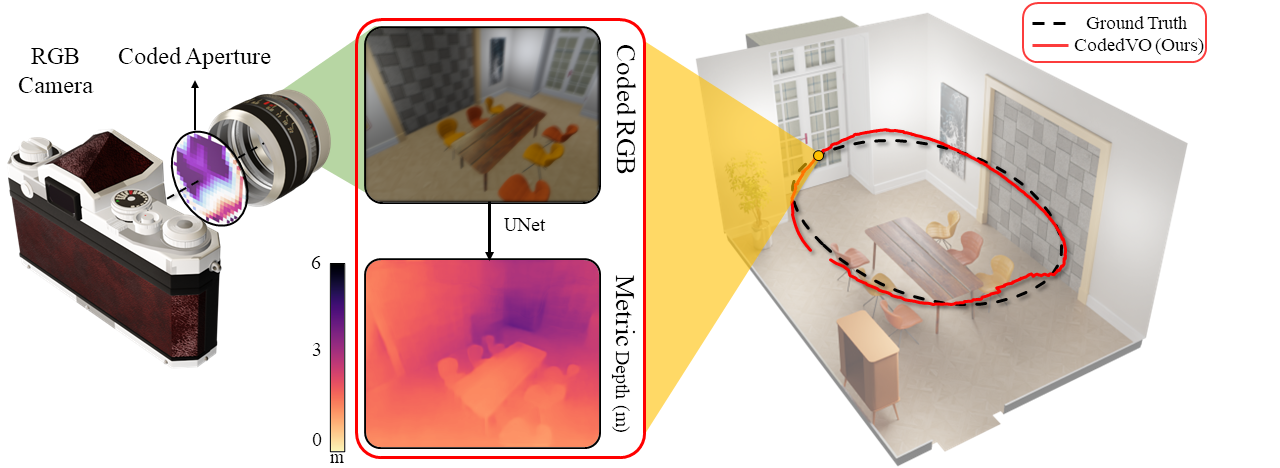
Unlocking Metric Depth
We leverage a transparent thin plate or coded aperture to create unique blur patterns at different distances, enabling metric depth prediction from a single RGB image.

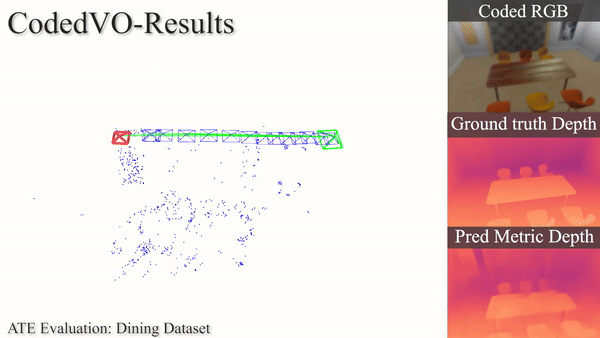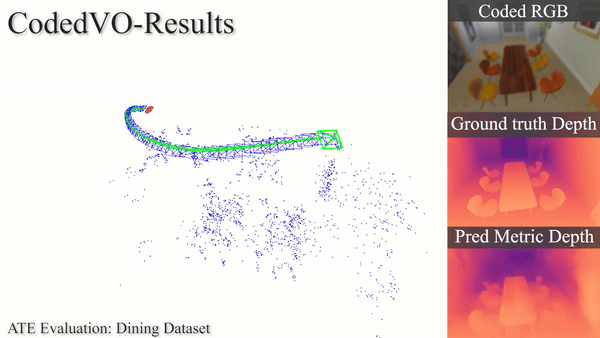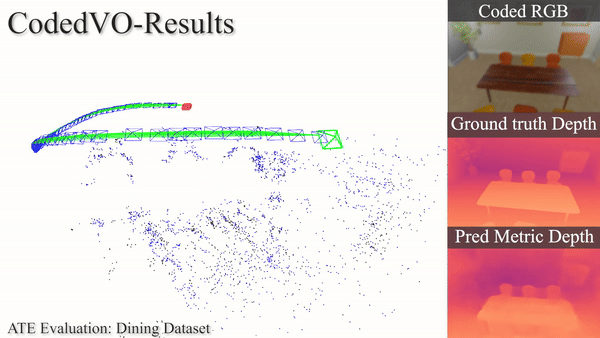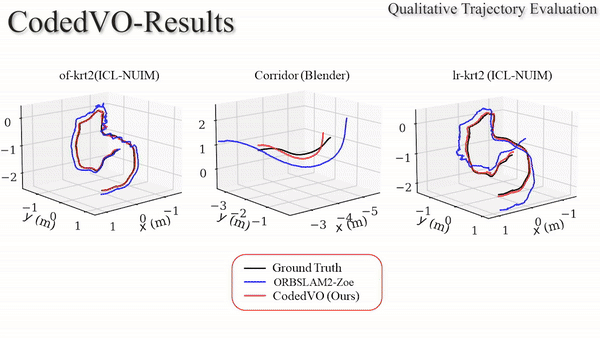
Autonomous robots often rely on monocular cameras for odometry estimation and navigation. However, the inherent challenge of scale ambiguity in monocular visual odometry remains a critical bottleneck. In this paper, we present CodedVO, a novel monocular visual odometry method that leverages optical constraints from coded apertures to resolve scale ambiguity. By integrating RGB and predicted metric depth using optical constraints, we achieve state-of-the-art performance in monocular visual odometry with a known scale. We evaluate our method in diverse indoor environments and demonstrate its robustness and adaptability. We achieve 0.08m average trajectory error in odometry evaluation in standard indoor odometry datasets.
Drawing inspiration from the evolution of eyes and pupils, researchers have developed coded apertures tailored for monocular camera systems. These aperture masks enable metric dense depth estimation from a single view by utilizing depth cues from defocus. However, these computational imaging methods are underutilized and not well-explored in the field of robot autonomy. This paper introduces CodedVO, a novel visual odometry method that leverages the metric depth maps from the geometrical constraints of a coded camera system and achieves state-of-the-art monocular odometry performance.
We leverage a transparent thin plate or coded aperture to create unique blur patterns at different distances, enabling metric depth prediction from a single RGB image.
Using a coded aperture for metric depth information, we enhance odometry accuracy achieving state-of-the-art results on unseen datasets and indoor navigation benchmarks
@ARTICLE{10564186,
author={Shah, Sachin and Rajyaguru, Naitri and Singh, Chahat Deep and Metzler, Christopher and Aloimonos, Yiannis},
journal={IEEE Robotics and Automation Letters},
title={CodedVO: Coded Visual Odometry},
year={2024},
doi={10.1109/LRA.2024.3416788}}