
Abstract
There has been a lot of interest in grounding natural language to physical entities through visual context. While Vision Language Models (VLMs) can ground linguistic instructions to visual sensory information, they struggle with grounding non-visual attributes, like the weight of an object. Our key insight is that non-visual attribute can be effectively achieved by active perception guided by visual reasoning. To this end, we present a perception-action programming API that consists of VLMs and Large Language Models (LLMs) as backbones, together with a set of robot control functions. When prompted with this API and a natural language query, an LLM generates a program to actively identify attributes given an input image. Offline testing on the Odd-One-Out dataset demonstrates that our framework outperforms vanilla VLMs in detecting attributes like relative object location, size, and weight. Online testing in realistic household scenes on AI2-THOR and a real robot demonstration on a DJI RoboMaster EP robot highlight the efficacy of our approach.
Framework Architecture

We describe our end-to-end framework for embodied attribute detection. The LLM receives as input a perception API with LLMs and VLMs as backbones, an action API based on a Robot Control API, a natural language (NL) instruction from a user, and a visual scene observation. It then produces a python program that combines LLM and VLM function calls with robot actions to actively reason about attribute detection.
Perception-Action API

The API consists of an \(\mathtt{ImagePatch}\) class and a \(\mathtt{Robot}\) action class with methods and examples of their uses in the form of docstrings. Inspired by ViperGPT, \(\mathtt{ImagePatch}\) supports Open-Vocabulary object Detection (OVD), Visual Question Answering (VQA), and answering textual queries through the \(\mathtt{find}\), \(\mathtt{visual\_query}\), and \(\mathtt{language\_query}\) functions, respectively. The \(\mathtt{Robot}\) class has a list of sensors as a member variable, and a set of functions to focus on the center of an image (\(\mathtt{focus\_on\_patch}\)), measure weight (\(\mathtt{measure\_weight}\)) and distance (\(\mathtt{measure\_weight}\)), navigate to an object (\(\mathtt{go\_to\_coords}\) and \(\mathtt{go\_to\_object}\)) or pick (\(\mathtt{pick\_up}\)) and place it (\(\mathtt{put\_on}\)). The input prompt includes the API with guidelines on how to use it, and a natural language query.
Offline Testing (Attribute Detection)
API vs OVD and VQA
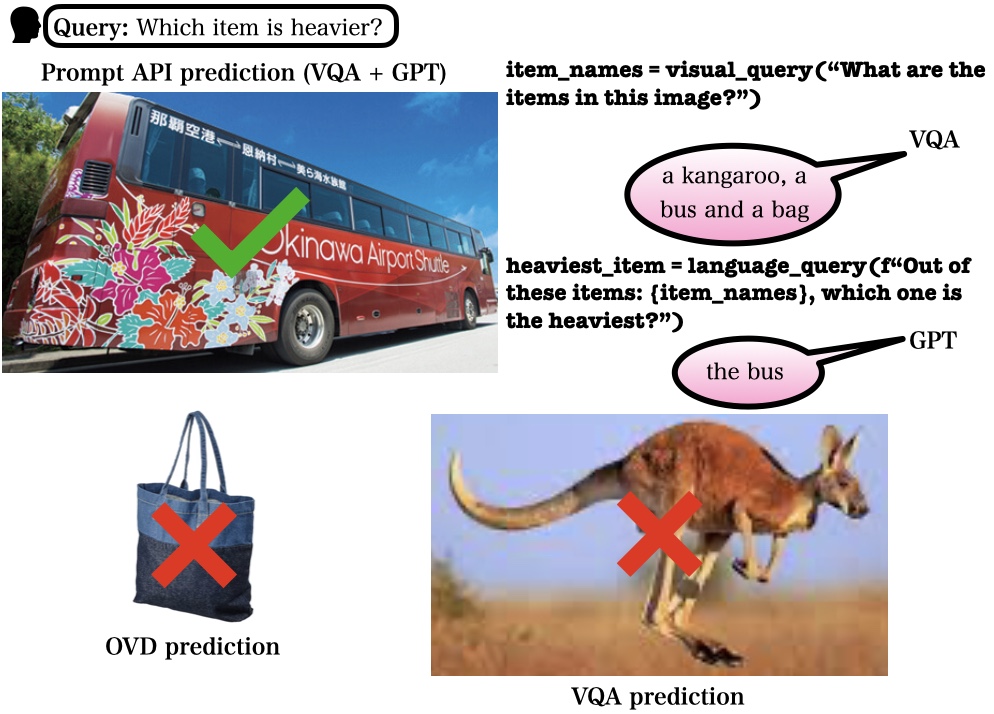
API vs OVD
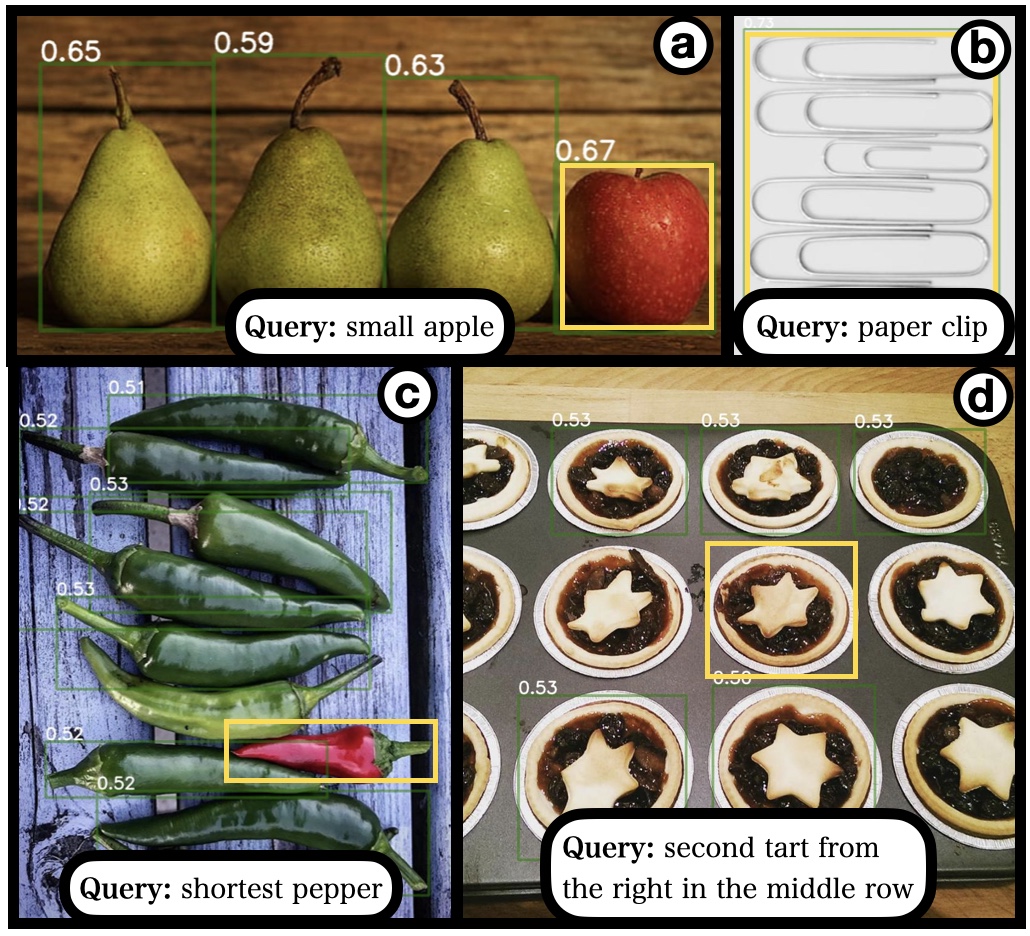
In order to evaluate the visual reasoning capabilities of the API, we build a dataset based on Odd-One Out (O3) with relative object location, size, and weight queries and compare the perception API part with OVD and VQA. On the left, OVD and VQA fail to identify the heaviest object but the API LLM-generated code returns the correct answer. On the right, OVD and API predictions are shown with green and yellow bounding boxes. Image a shows an example of agreement between OVD and the API, b shows a mutual failure case, and c and d show cases where the API outperforms OVD.
AI2-THOR Simulation
Distance Estimation

Weight Estimation

We integrate the perception-action API in different AI2-THOR household environments. In the Distance Estimation task (left) the robot has to identify which object is closer to its camera. We use the question ”which one is closer to me?” followed by the objects in question. Our API invokes an active perception behavior that computes the distance to an object by fixating on it with a call to \(\mathtt{focus\_on\_patch}\). It then calls the \(min\) function to find the smallest distance. In Weight Estimation (right), the invoked behavior determines the weight of an object by navigating to it (\(\mathtt{go\_to\_object}\)), picking it up (\(\mathtt{pick\_up}\)) and calling \(\mathtt{measure\_weight}\), which simulates the use of a force/torque sensor mounted on the wrist of the robot arm.
Robot Demonstration

We integrate our framework into a RoboMaster EP robot with the \(\mathtt{Robot}\) class as a wrapper over the RoboMaster SDK. The robot is connected to a (local) computer via wifi connection and communicates with a (remote) computing cluster through a client-server architecture running on an SSH tunnel. We only run OVD on the first frame captured by the robot camera to reduce latency, and then track the corresponding position(s) with the Kanade–Lucas–Tomasi (KLT) feature tracker (github implementation). We tune a lateral PID controller to align the geometric centers of the robot camera and the object bounding box to implement the \(\mathtt{focus\_on\_patch}\) function. To approach an object and implement the \(\mathtt{go\_to\_object}\) function we use an infrared distance sensor mounted on the front of the robot and tune a longitudinal PID controller. The video above shows the robot performing active distance estimation using our framework.
Paper
|
Angelos Mavrogiannis, Dehao Yuan, Yiannis Aloimonos
|
|
