Active Vision
at PRG Lab
The general concept of Active Vision is to move in such a way to make the perception problem easier. We work on designing both these “movement” and “perception” algorithms.
Researchers
Recent Research
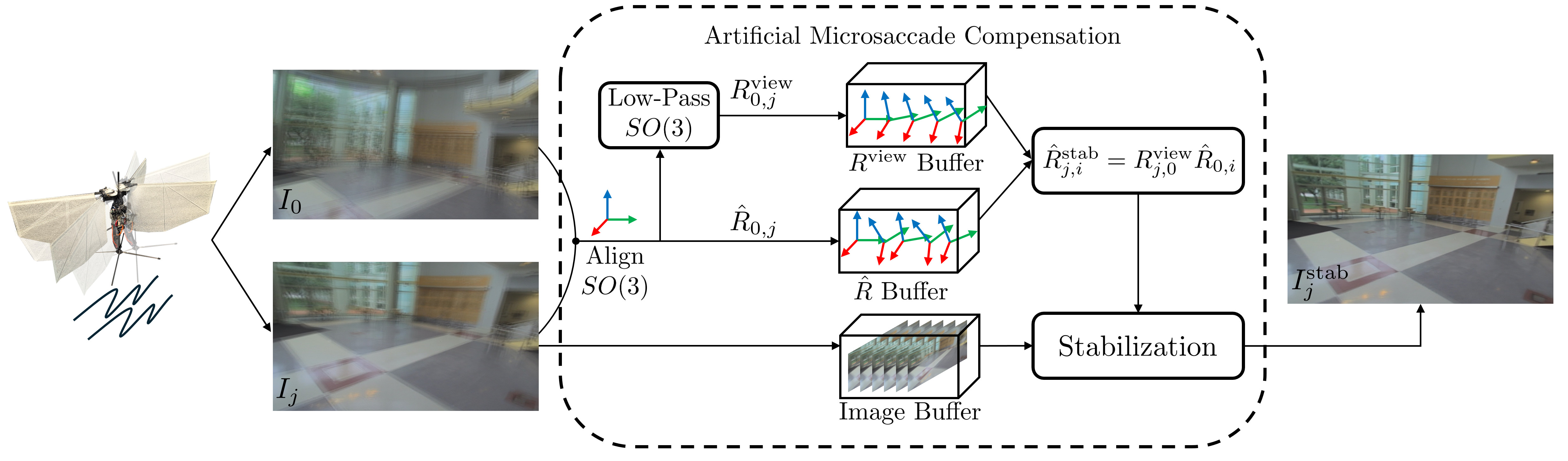
Artificial Microsaccade Compensation: Stable Vision for an Ornithopter
Levi Burner, Guido C.H.E. de Croon, Yiannis Aloimonos
Animals with foveated vision, experience microsaccades, small, rapid eye movements that they are not aware of. Inspired by this phenomenon, we develop a method for "Artificial Microsaccade Compensation". It can stabilize video captured by a tailless ornithopter that has resisted attempts to use camera-based sensing because it shakes at 12-20 Hz. Our approach minimizes changes in image intensity by optimizing over 3D rotation represented in SO(3). This results in a stabilized video, computed in real time, suitable for human viewing, and free from distortion.
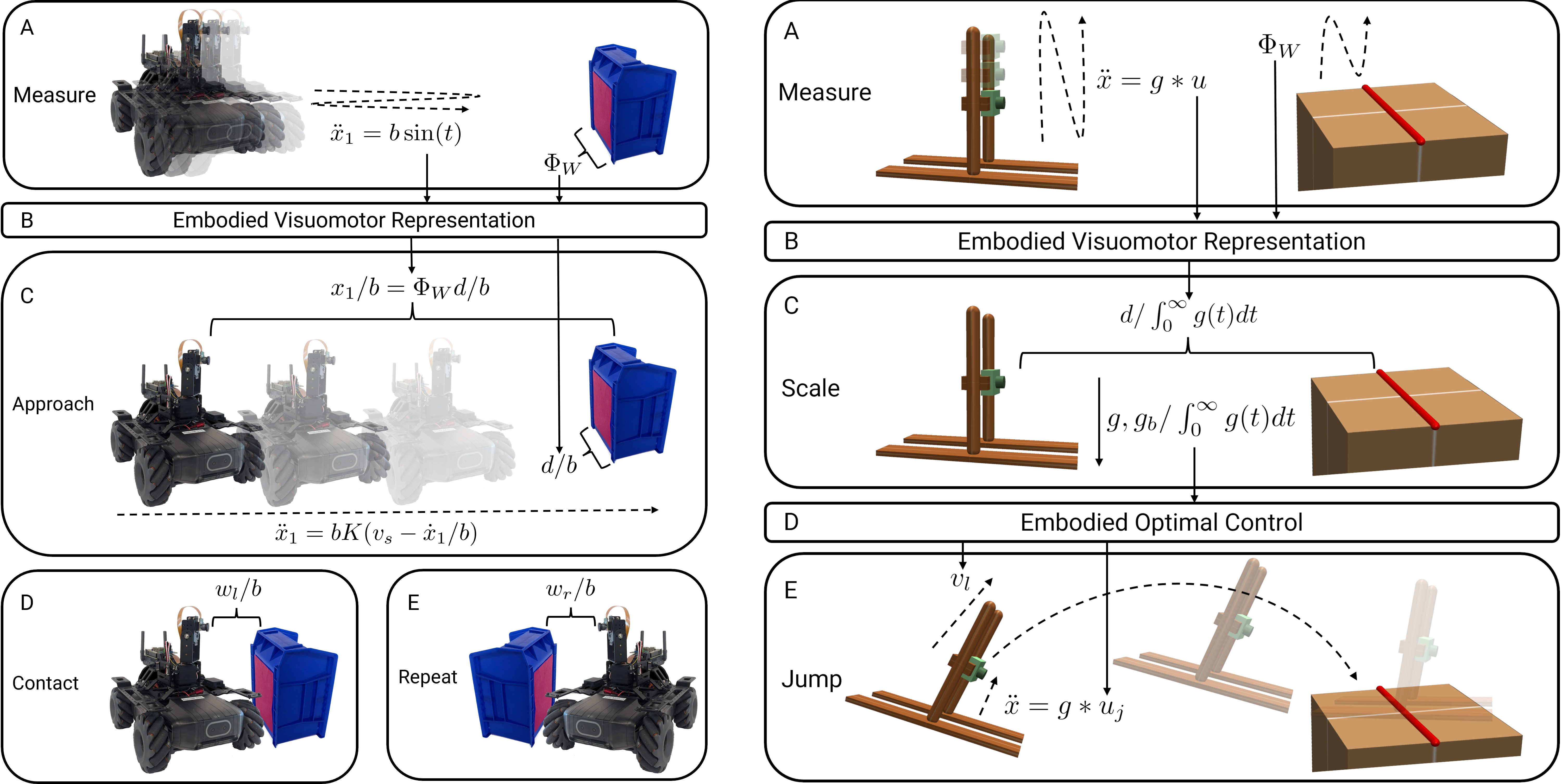
Embodied Visuomotor Representation
Levi Burner, Cornelia Fermüller, Yiannis Aloimonos
We introduce Embodied Visuomotor Representation, a methodology for inferring distance in a unit implied by action. With it a robot without knowledge of its size, environmental scale, or strength can quickly learn to touch and clear obstacles within seconds of operation. Likewise, in simulation, an agent without knowledge of its mass or strength can successfully jump across a gap of unknown size after a few test oscillations.
Learning Normal Flow Directly From Events
Dehao Yuan, Levi Burner, Jiayi Wu, Minghui Liu, Jingxi Chen, Yiannis Aloimonos, Cornelia Fermüller
Normal flow estimators are predominantly model-based and suffer from high errors. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, producing temporally and spatially sharp predictions. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets.

Odometry Without Correspondence from Inertially Constrained Ruled Surfaces
Chenqi Zhu, Levi Burner, Yiannis Aloimonos
Correspondence between two consecutive frames can be costly to compute and suffers from varying accuracy. If a camera observes a straight line as it moves, the image of the line sweeps a smooth surface in image-space time. Analyzing its shape gives information about odometry. Further, its estimation requires only differentially computed updates from point-to-line associations. By constraining the surfaces with the inertia measurements from an onboard IMU sensor, the dimensionality of the solution space is greatly reduced.

Extremum Seeking Controlled Wiggling for Tactile Insertion
Levi Burner, Pavan Mantripragada, Gabriele M. Caddeo, Lorenzo Natale, Cornelia Fermüller, Yiannis Aloimonos
When humans perform complex insertion tasks such as pushing a cup into a cupboard, routing a cable, or putting a key in a lock, they wiggle the object and adapt the process through tactile feedback. A similar robotic approach has not been developed. We study an extremum seeking control law that wiggles end effector pose to maximize insertion depth while minimizing strain measured by a GelSight Mini sensor.

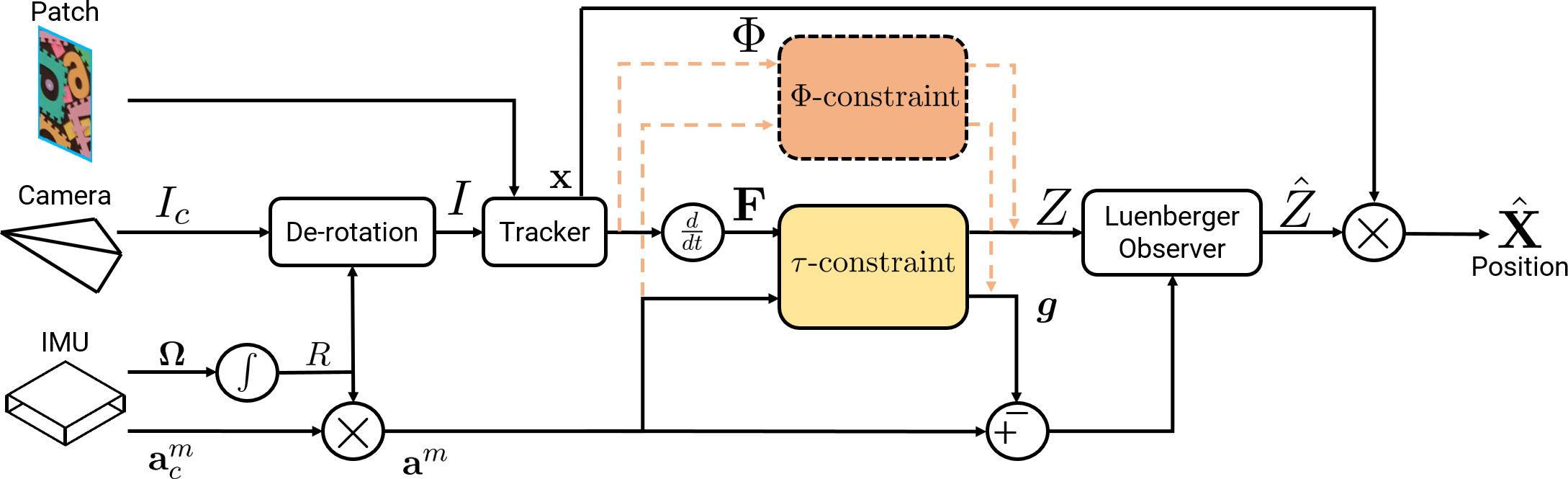
TTCDist: Fast Distance Estimation From an Active Monocular Camera Using Time-to-Contact
Levi Burner, Nitin J. Sanket, Cornelia Fermüller, Yiannis Aloimonos
Distance estimation from vision is fundamental for a myriad of robotic applications such as navigation, manipulation, and planning. Inspired by the mammal's visual system, which gazes at specific objects, we develop two novel constraints relating time-to-contact, acceleration, and distance that we call the -constraint and -constraint. They allow an active (moving) camera to estimate depth efficiently and accurately while using only a small portion of the image. The constraints are applicable to range sensing, sensor fusion, and visual servoing.
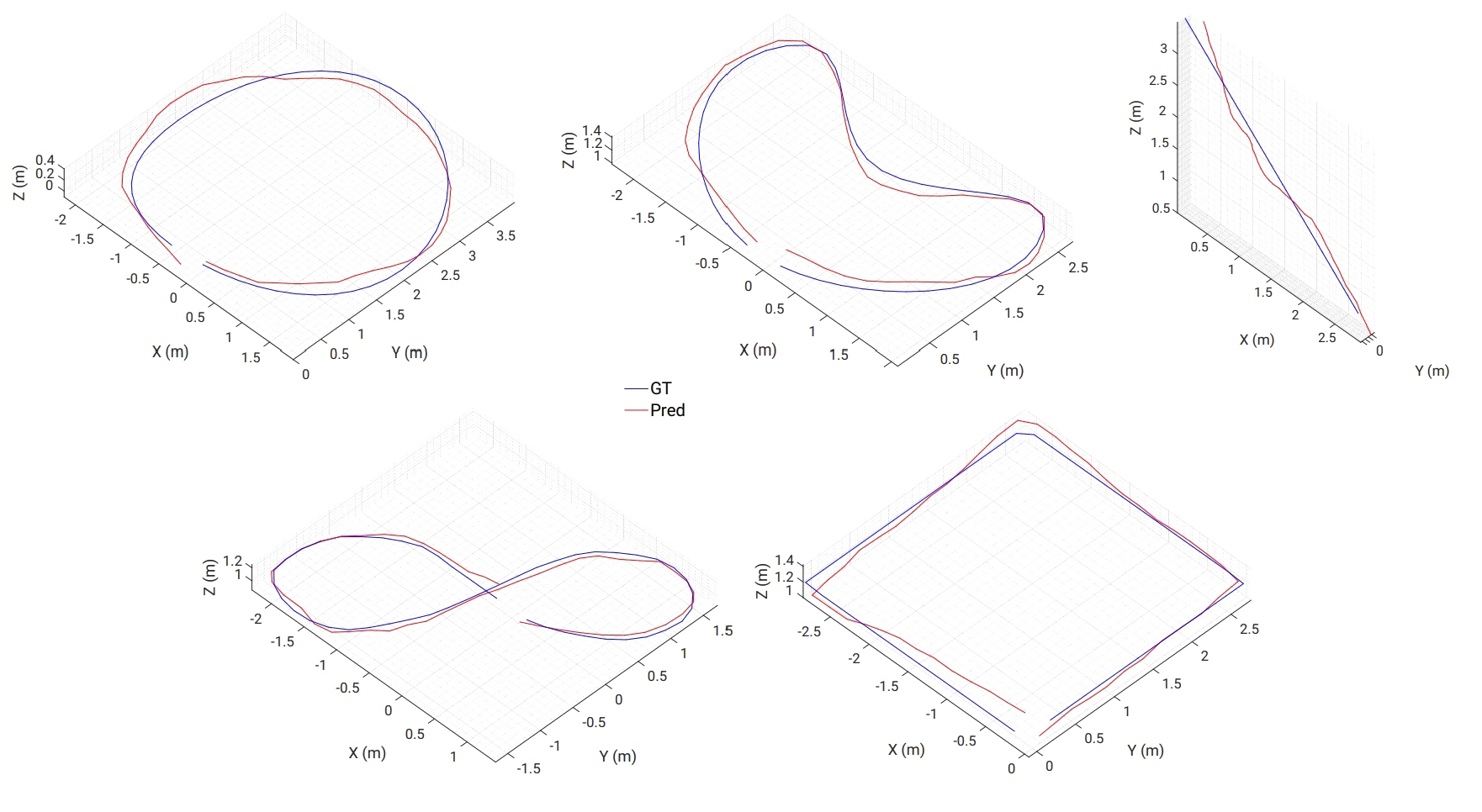
PRGFlow: Benchmarking SWAP-Aware Unified Deep Visual Inertial Odometry
Nitin J. Sanket, Chahat Deep Singh, Cornelia Fermüller, Yiannis Aloimonos
Odometry on aerial robots has to be of low latency and high robustness whilst also respecting the Size, Weight, Area and Power (SWAP) constraints as demanded by the size of the robot. A combination of visual sensors coupled with Inertial Measurement Units (IMUs) has proven to be the best combination to obtain robust and low latency odometry on resource-constrained aerial robots. Recently, deep learning approaches for Visual Inertial fusion have gained momentum due to their high accuracy and robustness. However, the remarkable advantages of these techniques are their inherent scalability (adaptation to different sized aerial robots) and unification (same method works on different sized aerial robots) by utilizing compression methods and hardware acceleration, which have been lacking from previous approaches. We present a deep learning approach for visual translation estimation and loosely fuse it with an Inertial sensor for full 6DoF odometry estimation. We also present a detailed benchmark comparing different architectures, loss functions and compression methods to enable scalability. We evaluate our network on the MSCOCO dataset and evaluate the VI fusion on multiple real-flight trajectories.
EVDodgeNet: Deep Dynamic Obstacle Dodging with Event Cameras
Nitin J. Sanket, Chethan M. Parameshwara, Chahat Deep Singh, Ashwin V. Kuruttukulam, Cornelia Fermüller, Davide Scaramuzza, Yiannis Aloimonos
Dynamic obstacle avoidance on quadrotors requires low latency. A class of sensors that are particularly suitable for such scenarios are event cameras. In this paper, we present a deep learning based solution for dodging multiple dynamic obstacles on a quadrotor with a single event camera and onboard computation. Our approach uses a series of shallow neural networks for estimating both the ego-motion and the motion of independently moving objects. The networks are trained in simulation and directly transfer to the real world without any fine-tuning or retraining. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with obstacles of different shapes and sizes, achieving an overall success rate of 70% including objects of unknown shape and a low light testing scenario. To our knowledge, this is the first deep learning based solution to the problem of dynamic obstacle avoidance using event cameras on a quadrotor. Finally, we also extend our work to the pursuit task by merely reversing the control policy, proving that our navigation stack can cater to different scenarios.

GapFlyt: Active Vision Based Minimalist Structure-less Gap Detection For Quadrotor Flight
Nitin J Sanket, Chahat Deep Singh, Kanishka Ganguly, Cornelia Fermüller, Yiannis Aloimonos
In this paper, we propose this framework of bio-inspired perceptual design for quadrotors. We use this philosophy to design a minimalist sensori-motor framework for a quadrotor to fly though unknown gaps without a 3D reconstruction of the scene using only a monocular camera and onboard sensing. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different settings and window shapes, achieving a success rate of 85% at 2.5m/s even with a minimum tolerance of just 5cm.

SalientDSO: Bringing Attention to Direct Sparse Odometry
Huai-Jen Liang, Nitin J. Sanket, Cornelia Fermüller, Yiannis Aloimonos
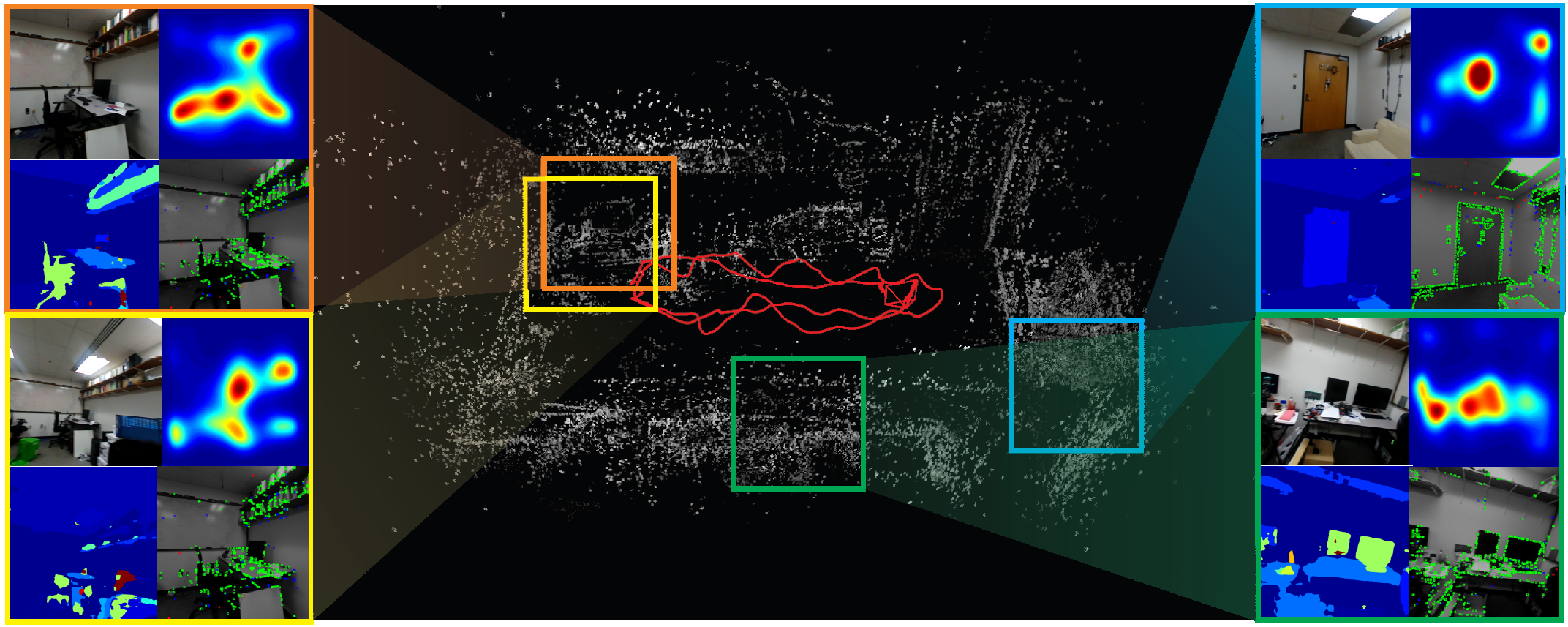
Although cluttered indoor scenes have a lot of useful high-level semantic information which can be used for mapping and localization, most Visual Odometry (VO) algorithms rely on the usage of geometric features such as points, lines and planes. Lately, driven by this idea, the joint optimization of semantic labels and obtaining odometry has gained popularity in the robotics community. The joint optimization is good for accurate results but is generally very slow. At the same time, in the vision community, direct and sparse approaches for VO have stricken the right balance between speed and accuracy. We merge the successes of these two communities and present a way to incorporate semantic information in the form of visual saliency to Direct Sparse Odometry - a highly successful direct sparse VO algorithm. We also present a framework to filter the visual saliency based on scene parsing. Our framework, SalientDSO, relies on the widely successful deep learning based approaches for visual saliency and scene parsing which drives the feature selection for obtaining highly-accurate and robust VO even in the presence of as few as 40 point features per frame. We provide extensive quantitative evaluation of SalientDSO on the ICL-NUIM and TUM monoVO datasets and show that we outperform DSO and ORB-SLAM - two very popular state-of-the-art approaches in the literature. We also collect and publicly release a CVL-UMD dataset which contains two indoor cluttered sequences on which we show qualitative evaluations. To our knowledge this is the first paper to use visual saliency and scene parsing to drive the feature selection in direct VO.
Our Sponsors














info[at]prg.cs.umd.edu
Researchers





Recent Research
Artificial Microsaccade Compensation: Stable Vision for an Ornithopter
Levi Burner, Guido C.H.E. de Croon, Yiannis Aloimonos
Animals with foveated vision, experience microsaccades, small, rapid eye movements that they are not aware of. Inspired by this phenomenon, we develop a method for "Artificial Microsaccade Compensation". It can stabilize video captured by a tailless ornithopter that has resisted attempts to use camera-based sensing because it shakes at 12-20 Hz. Our approach minimizes changes in image intensity by optimizing over 3D rotation represented in SO(3). This results in a stabilized video, computed in real time, suitable for human viewing, and free from distortion.
Embodied Visuomotor Representation
Levi Burner, Cornelia Fermüller, Yiannis Aloimonos
We introduce Embodied Visuomotor Representation, a methodology for inferring distance in a unit implied by action. With it a robot without knowledge of its size, environmental scale, or strength can quickly learn to touch and clear obstacles within seconds of operation. Likewise, in simulation, an agent without knowledge of its mass or strength can successfully jump across a gap of unknown size after a few test oscillations.
Learning Normal Flow Directly From Events
Dehao Yuan, Levi Burner, Jiayi Wu, Minghui Liu, Jingxi Chen, Yiannis Aloimonos, Cornelia Fermüller
Normal flow estimators are predominantly model-based and suffer from high errors. Using a local point cloud encoder, our method directly estimates per-event normal flow from raw events, producing temporally and spatially sharp predictions. Extensive experiments demonstrate our method achieves better and more consistent performance than state-of-the-art methods when transferred across different datasets.
Odometry Without Correspondence from Inertially Constrained Ruled Surfaces
Chenqi Zhu, Levi Burner, Yiannis Aloimonos
Correspondence between two consecutive frames can be costly to compute and suffers from varying accuracy. If a camera observes a straight line as it moves, the image of the line sweeps a smooth surface in image-space time. Analyzing its shape gives information about odometry. Further, its estimation requires only differentially computed updates from point-to-line associations. By constraining the surfaces with the inertia measurements from an onboard IMU sensor, the dimensionality of the solution space is greatly reduced.
Extremum Seeking Controlled Wiggling for Tactile Insertion
Levi Burner, Pavan Mantripragada, Gabriele M. Caddeo, Lorenzo Natale, Cornelia Fermüller, Yiannis Aloimonos
When humans perform complex insertion tasks such as pushing a cup into a cupboard, routing a cable, or putting a key in a lock, they wiggle the object and adapt the process through tactile feedback. A similar robotic approach has not been developed. We study an extremum seeking control law that wiggles end effector pose to maximize insertion depth while minimizing strain measured by a GelSight Mini sensor.
TTCDist: Fast Distance Estimation From an Active Monocular Camera Using Time-to-Contact
Levi Burner, Nitin J. Sanket, Cornelia Fermüller, Yiannis Aloimonos
Distance estimation from vision is fundamental for a myriad of robotic applications such as navigation, manipulation, and planning. Inspired by the mammal's visual system, which gazes at specific objects, we develop two novel constraints relating time-to-contact, acceleration, and distance that we call the -constraint and -constraint. They allow an active (moving) camera to estimate depth efficiently and accurately while using only a small portion of the image. The constraints are applicable to range sensing, sensor fusion, and visual servoing.
PRGFlow: Benchmarking SWAP-Aware Unified Deep Visual Inertial Odometry
Nitin J. Sanket, Chahat Deep Singh, Cornelia Fermüller, Yiannis Aloimonos
Odometry on aerial robots has to be of low latency and high robustness whilst also respecting the Size, Weight, Area and Power (SWAP) constraints as demanded by the size of the robot. A combination of visual sensors coupled with Inertial Measurement Units (IMUs) has proven to be the best combination to obtain robust and low latency odometry on resource-constrained aerial robots. Recently, deep learning approaches for Visual Inertial fusion have gained momentum due to their high accuracy and robustness. However, the remarkable advantages of these techniques are their inherent scalability (adaptation to different sized aerial robots) and unification (same method works on different sized aerial robots) by utilizing compression methods and hardware acceleration, which have been lacking from previous approaches. We present a deep learning approach for visual translation estimation and loosely fuse it with an Inertial sensor for full 6DoF odometry estimation. We also present a detailed benchmark comparing different architectures, loss functions and compression methods to enable scalability. We evaluate our network on the MSCOCO dataset and evaluate the VI fusion on multiple real-flight trajectories.
EVDodgeNet: Deep Dynamic Obstacle Dodging with Event Cameras
Nitin J. Sanket, Chethan M. Parameshwara, Chahat Deep Singh, Ashwin V. Kuruttukulam, Cornelia Fermüller, Davide Scaramuzza, Yiannis Aloimonos
Dynamic obstacle avoidance on quadrotors requires low latency. A class of sensors that are particularly suitable for such scenarios are event cameras. In this paper, we present a deep learning based solution for dodging multiple dynamic obstacles on a quadrotor with a single event camera and onboard computation. Our approach uses a series of shallow neural networks for estimating both the ego-motion and the motion of independently moving objects. The networks are trained in simulation and directly transfer to the real world without any fine-tuning or retraining. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with obstacles of different shapes and sizes, achieving an overall success rate of 70% including objects of unknown shape and a low light testing scenario. To our knowledge, this is the first deep learning based solution to the problem of dynamic obstacle avoidance using event cameras on a quadrotor. Finally, we also extend our work to the pursuit task by merely reversing the control policy, proving that our navigation stack can cater to different scenarios.
GapFlyt: Active Vision Based Minimalist Structure-less Gap Detection For Quadrotor Flight
Nitin J Sanket, Chahat Deep Singh, Kanishka Ganguly, Cornelia Fermüller, Yiannis Aloimonos
In this paper, we propose this framework of bio-inspired perceptual design for quadrotors. We use this philosophy to design a minimalist sensori-motor framework for a quadrotor to fly though unknown gaps without a 3D reconstruction of the scene using only a monocular camera and onboard sensing. We successfully evaluate and demonstrate the proposed approach in many real-world experiments with different settings and window shapes, achieving a success rate of 85% at 2.5m/s even with a minimum tolerance of just 5cm.
SalientDSO: Bringing Attention to Direct Sparse Odometry
Huai-Jen Liang, Nitin J. Sanket, Cornelia Fermüller, Yiannis Aloimonos
Although cluttered indoor scenes have a lot of useful high-level semantic information which can be used for mapping and localization, most Visual Odometry (VO) algorithms rely on the usage of geometric features such as points, lines and planes. Lately, driven by this idea, the joint optimization of semantic labels and obtaining odometry has gained popularity in the robotics community. The joint optimization is good for accurate results but is generally very slow. At the same time, in the vision community, direct and sparse approaches for VO have stricken the right balance between speed and accuracy. We merge the successes of these two communities and present a way to incorporate semantic information in the form of visual saliency to Direct Sparse Odometry - a highly successful direct sparse VO algorithm. We also present a framework to filter the visual saliency based on scene parsing. Our framework, SalientDSO, relies on the widely successful deep learning based approaches for visual saliency and scene parsing which drives the feature selection for obtaining highly-accurate and robust VO even in the presence of as few as 40 point features per frame. We provide extensive quantitative evaluation of SalientDSO on the ICL-NUIM and TUM monoVO datasets and show that we outperform DSO and ORB-SLAM - two very popular state-of-the-art approaches in the literature. We also collect and publicly release a CVL-UMD dataset which contains two indoor cluttered sequences on which we show qualitative evaluations. To our knowledge this is the first paper to use visual saliency and scene parsing to drive the feature selection in direct VO.
Our Sponsors